SQLP를 준비하며 "친절한 sql 튜닝" 책 6장 DML 튜닝 기본 DML 튜닝 부분을 정리한 내용 입니다.
친절한SQL튜닝 도서
6장-DML 튜닝
6.1 기본 DML 튜닝
6.1.1 DML 성능에 영향을 미치는 요소
- 인덱스
- 무결성 제약
- 조건절
- 서브쿼리
- Redo 로깅
- Undo 로깅
- Lock
- 커밋
인덱스와 DML 성능
Freelist
테이블마다 데이터 입력이 가능한(여유 공간이 있는)블록 목록
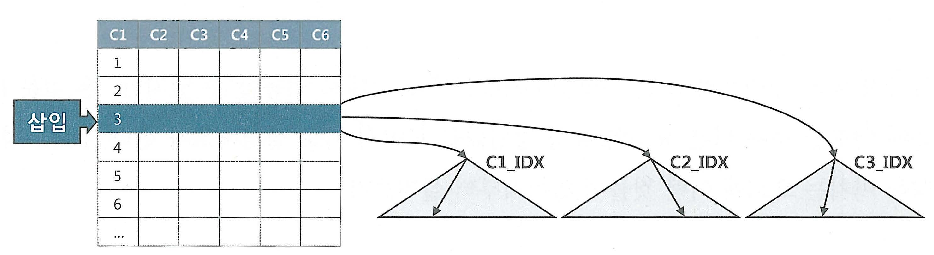

- 테이블에 레코드를 입력하면, 인덱스에도 입력해야 한다.
- 테이블의 경우 Freelist를 통해 입력할 블록을 할당, 인덱스는 정렬된 자료구조 이므로 수직적 탐색을 통해 입력(INSERT)할 블록을 찾아야 한다.
- 삭제(DELETE)시 테이블은 레코드 하나만 삭제, 인덱스는 레코드 모두 찾아서 삭제
- 변경(UPDATE)시 변경된 컬럼을 참조하는 인덱스만 찾아서 변경 하면 된다. 대신 정렬된 자료구조이기 때문에 삭제 후 삽입하는 방식으로 처리
- 인덱스 개수가 DML에 미치는 영향은 매우 크기 때문에 핵심 트랜젝션 테이블에서 인덱스를 줄이면 TPS(Transaction Per Second)는 그 만큼 향상 된다.
무결성 제약과 DML 성능
데이터베이스의 데이터 무결성 규칙
- 개체 무결성(Entity Integrity)
- 참조 무결성(Referential Integrity)
- 도메인 무결성(Domain Integrity)
- 사용자 정의 무결성(또는 업무 제약 조건)
DBMS에서 PK, FK, Check, Not null 같은 제약을 설정하면 더 완벽하게 데이터 무결성을 지켜낼 수 있음.
PK,FK 제약은 실제 데이터를 조회해 봐야 하기 때문에, Check, Not null 제약보다 성능에 더 큰 영향을 미친다.
제약에 따른 소요시간

조건절, 서브쿼리와 DML 성능
조건절. 서브쿼리를 포함하는 경우에도 SELECT 문과 실행계획이 다르지 않으므로 인덱스 튜닝 원리를 그대로 적용할 수 있다.
Redo 로깅과 DML 성능
- 오라클은 데이터파일과 컨트롤 파일에 가해지는 모든 변경사항을 Redo 로그에 기록
- Redo 로그는 트랜잭션 데이터가 어떤 이유에서건 유실됐을 때, 트랜잭션을 재현함으로써 유실 이전 상태로 복구하는데 사용된다.
- DML을 수행할 때마다 Redo 로그를 생성해야 하므로 Redo 로깅은 DML 성능에 영향을 미친다.
Redo 로그의 용도
- Database Recovery
- Cache Recovery(Instance Recovery 시 roll forward 단계)
- Fast Commit
Database Recovery
- 물리적으로 디스크가 깨지는 등의 Media Fail 발생 시 데이터베이스를 복구하기 위해 사용
- 복구 시 온라인 Redo 로그를 백업해 둔 Archived Redo 로그를 이용.(Media Recovery)
Cache Recovery(Instance Recovery)
- 버퍼캐시는 휘발성이기 때문에 캐시에 저장된 변경사항이 디스크 상에 데이터 블록에 기록되지 않은 상태에서 인스턴스가 비정상적으로 종료되면, 그때까지 작업내용을 모두 잃게 된다.
- 이러한 트랜잭션 데이터 유실에 대비하기 위해 Redo 로그를 남긴다.
FastCommit
- 변경된 메모리 버퍼 블록을 디스크 상의 블록에 반영 시 랜덤 엑세스 방식으로 이루어지므로 매우 느린 반면, 로그는 Append 방식으로 기록 해 상대적으로 빠르다.
- 트랜잭션에 의한 변경 사항을 Append 방식으로 빠르게 로그 파일에 기록하고, 변경된 메모리 버퍼블록과 데이터파일 블록 간 동기화는 적절한 수단(DBWr, Checkpoint)을 이용해 배치 방식으로 일괄 수행 한다.
- 사용자의 갱신내용이 메모리상 버퍼믈록에만 기록된 채 아직 디스크에 기록되지 않았지만, Redo 로그를 믿고 빠르게 커밋을 완료한다는 의미에서 Fast Commit이라고 불린다.
Undo 로깅과 DML 성능
Redo VS Undo

- Redo는 트랜잭션을 재현함으로써 과거를 현재 상태로 돌리는데 사용하기 떄문에 트랜잭션을 재현하는데 필요한 정보를 로깅한다.
- Undo는 트랜잭션을 롤백함으로써 현재를 과거 상태로 되돌리는데 사용하기 때문에 변경된 블록을 이전 상태로 되돌리는데 필요한 정보를 로깅한다.
- DML을 수행할 때 마다 Undo를 생성해야 하므로 Undo 로깅은 DML 성능에 영향을 미치며, Undo를 남기지 않는 방법은 없다.
Redo / Undo의 자세한 설명
https://loosie.tistory.com/527
https://blog.naver.com/kmymk/110081009687
Undo의 용도
오라클은 데이터를 입력, 수정, 삭제할 때마다 Undo 세그먼트에 기록을 남기며, 데이터를 기록한 공간은 해당 트랜잭션이 커밋하는 순간 다른 트랜잭션이 재사용할 수 있는 상태로 바뀐다.
오래 커밋한 Undo 공간부터 재사용하므로 언젠가 다른 트랜잭션 데이터로 덮어쓰이면서 사라진다.
- Transaction Rollback
- Transaction Recovery(Instance Recovery 시 rollback 단계)
- Read Consistency
Transaction Rollback
- 트랜잭션에 의한 변경사항을 최종 커밋하지 않고 롤백하고자 할 때 사용
Transaction Recovery
- Instance Crash 발생 후 Redo를 이용해 roll forward 단계가 완료되면 최종 커밋 되지 않은 변경사항까지 모두 복구
- 시스템이 셧다운된 시점에 아직 커밋되지 않았던 트랜잭션을 모두 롤백 할 때 사용
Read Consistency
- ‘읽기 일관성(Read Consistency)’를 위해 사용
- 읽기 일관성을 위해 Consistent 모드로 데이터를 읽는 오라클에선 동지 트랜잭션이 많을수록 블록 I/O가 증가하면서 성능 저하
MVCC(Multi-Version Concurrency Control) 모델
MVCC 모델을 사용하는 오라클은 데이터를 Current, Consistant 두가지 모드로 읽는다.

- Current 모드 : 쿼리가 시작된 이후 다른 트랜잭션에 의해 변경된 블록을 만나면 원본 블록으로부터 복사본(CR Copy) 블록을 만들고, 거기에 Undo 데이터를 적용함으로 써 쿼리가 '시작된 시점'으로 되돌려서 읽는 방식(위 그림)
- Conssistent 모드 : 쿼리 SCN과 블록 SCN을 비교함으로써 쿼리 수행 도중에 블록이 변경됐는지를 확인하면서 데이터를 읽는 방식, 데이터를 읽다 블록 SCN이 쿼리 SCN보다 더 큰 블록을 만나면 복사본 블록을 만들고 Undo 데이터를 적용함으로써 쿼리 시작 시점으로 되돌려 읽는다.
- Undo 데이터가 다른 트랜잭션에 의해 재사용됨으로써 쿼리 시작 시점으로 되돌리는 작업에 실패할 때 Snapshot too old(ORA-01555) 에러가 발생
- SELECT문은 항상 Consistend 모드로 데이터를 읽는 반면, DML 문은 Consistent모드로 대상 레코드를 찾고, Current 모드로 추가/변경/삭제 한다.
- Consistent 모드로 DML 문이 '시작된 시점'에 존재했던 데이터 블록을 찾고, 다시 Current모드로 원본 블록을 찾아서 갱신
- SCN(System Commit Number)
- 오라클은 시스템에서 마지막 커밋이 발생한 시점정보를 SCN이라는 Global 변수값으로 관리하며 기본적으로 각 트랜잭션이 커밋할 때마다 1씩 증가
- 블록 SCN : 각 블록이 마지막으로 변경된 시점을 관리하기 위해 모든 블록 헤더에 SCN을 기록한다.
- 쿼리 SCN : 모든 쿼리는 Global 변수인 SCN 값을 먼저 확인하고서 읽기 작업을 시작한다.
Lock과 DML 성능
- Lock을 필요 이상으로 자주, 길게 사용하거나 레벨을 높일수록 DML 성능은 느려진다.
- Lock을 너무 적게, 짧게 사용하거나 필요한 레벨 이하로 낮추면 데이터 품질이 저하 된다.
- 성능과 데이터 품질은 트레이드 오프(Trade-off)관계여서 두 가지다 좋으려면 세심한 동시성 제어가 필요하다.
- 동시성제어란, 동시에 실행되는 트랜잭션 수를 최대화(고성능) 하면서 입력, 수정, 삭제, 검색 시 데이터 무결성을 유지(고품질)하기 위해 노력 하는 것을 말한다.
커밋과 DML 성능
DML을 완료할 수 있게 Lock을 푸는 열쇠가 커밋이기 때문에 DML이 Lock에 의해 블로킹 된 경우, 커밋은 DML 성능과 직결된다
- 커밋의 내부 메커니즘
- DB 버퍼 캐시
- DB에 접속한 사용자를 대신해 모든 일을 처리하는 서버 프로세스는 버퍼 캐시를 통해 데이터를 읽고 쓴다.
- 버퍼캐시에서 변경된 블록(Dirty 블록)을 모아 주기적으로 데이터파일에 일괄 기록하는 작업은 DBWR(Database Writer) 프로세스가 맡는다.
- Redo 로그버퍼
- 버퍼캐시에 가한 변경사항을 Redo 로그에도 기록하기 때문에 버퍼캐시 데이터가 유실되더라도 Redo 로그를 이용해 언제든 복구 가능하다.
- Redo 로그도 파일이기 때문에, Append 방식으로 기록해도 디스크 I/O라 느리다.
- Redo 로그 성능 문제를 해결하기위 해 Redo 로그 파일에 기록하기 전에 먼저 로그버퍼에 기록 해 성능 문제를 해결한다.
- 로그버퍼에 기록한 내용은 나중에 LGWR(Log Writer) 프로세스가 Redo 로그 파일에 일괄(Batch) 기록한다.
- 트랜잭션 데이터 저장 과정
Write Ahead Logging : 서버 프로세스가 버퍼블록에서 데이터 변경을 하기 전 Redo 로그 버퍼 에 기록, DBWR 프로세스가 Dirty 블록을 디스크에 기록 하는 것을 말함.
Log Force at Commit : 커밋 시점에는 Redo 로그 버퍼 내용을 로그 파일에 기록한다는 것을 말함.
- DML 문을 실행하면 Redo 로그버퍼에 변경사항을 기록
- 버퍼블록에서 데이터를 변경(레코드 추가/수정/삭제)한다. 물론, 버퍼캐시에서 블록을 찾지 못하면, 데이터파일에서 읽는 작업부터 한다.
- 커밋한다.
- LGWR 프로세스가 Redo 로그버퍼 내용을 로그 파일에 일괄 저장한다.
- DBWR 프로세스가 변경된 버퍼블록들은 데이터파일에 일괄 저장한다.
- 커밋 = 저장 버튼
- 문서 작업 도중에 '저장' 버튼을 누르는 것과 같으며, 서버 프로세스가 그때까지 했던 작업을 디스크에 기록하라는 명령어
- LG 프로세스에 신호를 보낸 후 작업을 완료했다는 신호를 받아야 다음 작업을 진행할 수 있는 Sync 이다.
- LGWR 프로세스가 Redo 로그를 기록하는 작업은 디스크 I/O 작업이다.
- DB 버퍼 캐시
6.1.2 데이터베이스 Call과 성능
데이터베이스 Call

- SQL Call은 세 단계로 나누어 실행된다.
- Parse Call : SQL 파싱과 최적화를 수행하는 단계. SQL과 실행계획을 라이브러리 캐시에서 찾으면, 최적화 단계는 생략 가능
- Execute Call : 말 그래로 SQL을 실행하는 단계다. DML은 이 단계에서 모든 과정이 끝나지만, SELECT 문은 Fetch 단계를 거친다.
- Fetch Call : 데이터를 읽어서 사용자에게 결합집합을 전송하는 과정으로 SELECT 문에서만 나타난다. 전송할 데이터가 많을 때는 Fetch Call이 여러 번 발생한다.
Call 발생에 따른 분류

- User Call
- 네트워크를 경유해 DBMS 외부로부터 인입되는 콜이며,최종 사용자는 맨 왼쪽 클라이언트 단에 위치한다.
- DBMS 입장에서 사용자는 AWS다.
- 3-Tier 아키넥처에서 User Call은 WAS(또는 AP서버) 서버에서 발생하는 Call 이다.
- Recursive Call
- DBMS 내부에서 발생하는 CALL
- SQL 파싱과 최적화 과정에서 발생하는 데이터 딕셔너리 조회, PL/SQL로 작성한 경우 사용자 정의 함수/프로시저/트리거에 내장된 SQL을 실행할 때 발생
6.1.4 인덱스 및 제약 해제를 통한 대량 DML 튜닝
대량 데이터를 적재하는 배치(Batch) 프로그램에서는 인덱스와 무결성 제약 조건을 해제함으로써 큰 성능개선 효과를 얻을 수 있다.
PK 제약과 인덱스 해제 1-PK 제약에 Unique 인덱스를 사용한 경우
-- pk 제약과 인덱스 해제
truncate table target;
-- 일반 인덱스 Unusable 상태로 변경
alter index target_x1 unusable;
-- 인덱스가 Unusable인 상태에서 데이터를 입력 하려면 skip_unusable_index 파라미터를 true로 설정
alter session set skip_unusable_indexs = true;- PK 제약과 인덱스를 해제
- 일반 인덱스 Unusable
PK제약과 인덱스 해제2 - PK 제약에 Non-Unique 인덱스를 사용한 경우
-- PK 인덱스를 Drop 하지 않고 Unusable 상태에서 데이터를 입력 하려면
-- PK 제약에 Non-Unique 인덱스를 사용
set timing off;
truncate table target;
alter table target drop primary key drop index;
create index target_pk on target(no, empno); -- Non-Unique 인덱스 생성
alter table target add
constraint target_pk primary key(no, empno)
using index target_pk; -- PK 제약에 Non_Unique 인덱스 사용하도록 지정
-- PK 제약 비활성화, 인덱스 Unusable 상태로 변경
-- PK 제약을 비활성화 헀지만, 인덱스는 Drop 하지 않고 남겨놓았다.
alter table target modify constraint target_pk disable keep index;
alter index target_pk unusable;
alter index target_x1 unusable;
6.1.5 수정가능 조인 뷰

- 수정가능 뷰를 활용하면 참조 테이블과 두 번 조인하는 비효율을 없앨 수 있다.
- "조인 뷰"는 FROM 절에 두 개 이상 테이블을 가진 뷰를 가르킨다.
- "수정가능 조인뷰"는 입력, 수정, 삭제가 허용되는 조인뷰를 말한다.
단, 1쪽 집합과 조인하는 M쪽 집합에만 입력, 수정, 삭제가 허용




- 첫번째 사진 쿼리는 1쪽 집합(DEPT)와 조인하는 M쪽 집합(EMP) 컬럼을 수정하므로 문제가 없어 보이지만
실제 수행해 보면 ORA-01779에러가 발생한다 - 세번째 사진 역시 DELETE,INSERT 시 ORA-01752에러가 발생한다.
- 이러한 에러가 발생하는 이유는 옵티마이저가 지금 어느 테이블이 1쪽 집합인지 알 수 없기 때문이다.
- 수정가능 조인 뷰를 통한 입력/수정/삭제가 가능하게 하려면 1쪽 집합에 PK 제약을 설정하거나 Unique 인덱스를 생성해야 한다.
- 네번째 사진 처럼 PK 제약을 설정하면 EMP 테이블은 '키-보존 테이블'이 되고, DEPT 테이블은 '비 키-보존 테이블'로 남는다.
키 보존 테이블이란?
- 조인된 결과집합을 통해서도 중복 값 없이 Unique하게 식별 가능한 테이블. 즉, 뷰에 rowid를 제공하는 테이블
6.1.6 MERGE문 활용
고객 테이블에 발생한 변경분 데이터를 DW에 반영하는 프로세스
1.전일 발생한 변경 데이터를 기간계 시스템으로부터 추출(Extraction)
CREATE TABLE CUSTOMER_DELTA AS
SELECT * FROM CUSTOMER
WHERE MOD_DT >= TRUNC(SYSDATE)-1
AND MOD_DT < TRUNC(SYSDATE);
2.CUSTOMER_DELTA 테이블을 DW 시스템으로 전송(Transportation)
3.DW 시스템으로 적재(Loading)
MERGE INTO CUSTOMER T USING CUSTOMER_DELTA S ON (T.CUST_ID=S.CUST_ID)
WHEN MATCHED THEN UPDATE
SET T.CUST_NM = S.CUST_NM, T.EMAIL=S.EMAIL
WHEN NOT MATCHED THEN INSERT
(CUST_ID, CUST_NM, EMAIL, TEL_NO, REGION, ADDR, REG_DT) VALUES
(S.CUST_ID, S.CUST_NM, S.EMAIL, S.TEL_NO, S.REGION, S.ADDR, S.REG_DT);- 데이터 적재 작업을 효과적으로 지원하기 위해 오라클 9i에서 merge 문이 도입
Merge문 실행 방식

- source 테이블 기준으로 target 테이블과 left Outer 방식으로 조인에 성공하면 UPDATE, 실패하면 INSERT 한다.
Optional Clauses
merge into customer t using customer_delta s on (t .cust_id == s .cust_id)
when matched then update
set t .cust_nm == s .cust_nm, t .email == s .email, ··· ;
merge into customer t using customer_delta s on (t.cust_id = s .cust_id)
when not matched then insert
(cust_id, cust_nm, email, tel_no, region, addr, reg_dt) values
(s . cust_id, s .cust_nm, s .email, s .tel_no, s .region, s .addr, s .reg_dt) ;- update와 insert를 선택적으로 처리할 수 있다.
-- 수정가능 조인뷰
update
(select d.deptno, d.avg_sal as d_avg_sal, e.avg_sal as e_avg_sal
from (select deptno, round(avg(sal), 2) avg_sal from emp group by deptno) e
, dept d
where d.deptno = e.deptno )
set d_avg_sal = e_avg_sal ;
-- merge 문
merge into dept d
using (select deptno, round(avg(sal), 2) avg_sal from emp group by deptno) e
on (d .deptno = e.deptno)
when matched then update set d.avg_sal = e.avg_sal;- 수정가능 조인뷰 기능을 merge로 대체할 수 있다.
Conditional Operations
merge into customer t using customer_delta s on (t.cust_id = s.cust_id)
when matched then update
set t.cust_nm = s.cust_nm, t.email = s email, ···
where reg_dt >= to_date( '20000101' , 'yyyymmdd' )
when not matched then insert
(cust_id, cust_nm, email, tel_no, region, addr, reg_dt) values
(s.cust_id, s.cust_nm, s.email, s.tel_no, s.region, s.addr, s.reg_dt)
where reg_dt < trunc(sysdate) ;- ON 절에 기술한 조인문 외에 추가로 조건절을 쓸 수 있다.
DELETE Clause
merge into customer t using customer_delta s on (t.cust_id = s.cust_id)
when matched then
update set t.cust_nm = s.cust_nm, t.email = s.email,
delete where t.withdraw_dt is not null -- 탈퇴일시가 null 이 아닌 레코드 삭제
when not matched then insert
(cust_id, cust_nm, email, tel_no, region, addr, reg_dt) values
(s.cust_id, s.cust_nm, s.email, s.tel_no, s.region, s.addr, s.reg_dt) ;
- 이미 저장된 데이터를 조건에 따라 지우는 기능 제공
- MERGE 문에서 UPDATE가 이루어진 결과로서 탈퇴일시(withdraw_dt)가 Null이 아닌 레코드만 삭제한다.즉, 탈퇴일시가 Null이 아니었어도 MERGE문을 수행한 결과가 Null이면 삭제하지 않는다.
- MERGE문 DELETE 절은 조인에 성공한 데이터만 삭제할 수 있다.
- DELETE 절은 조인에 성공한 데이터를 모두 UPDATE 하고서 그 결과 값이 DELETE WHERE조건절을 만족하면 삭제하는 기능
Merge Into 활용 예
-- 일반 쿼리
select count(*) into :cnt from dept where deptno = :val1 ;
if :cnt = 0 then
insert into dept(deptno, dname, loc ) values ( : val1, : val2, : val3) ;
else
update dept set dname = :val2, loc = :val3 where deptno = :val1 ;
end if;
-- merge 쿼리
merge into dept a
using (select :val1 deptno, :val2 dname, :val3 loc from dual) b
on (b .deptno = a.deptno)
when matched then
update set dname = b . dname, loc = b .loc
when not matched then
insert (a.deptno, a.dname, a.loc) values (b .deptno, b.dname, b.loc) ;
d- 일반 쿼리는 SQL을 '항상 두 번씩'(SELECT 한번, INSERT 또는 UPDATE)실행
- MERGE 문을 활용하면 SQL을 한번만 수행한다.
merge 안티패턴
MERGE INTO EMP T2
USING (SELECT T.ROWID AS RID , S.ENAME
FROM EMP T, EMP_SRC S
WHERE T.EMPNO = S.EMPNO
AND T: ENAME <> S . ENAME ) S
ON (T2.ROWID = S.RID)
WHEN MATCHED THEN UPDATE SET T2.ENAME = S.ENAME;- updae 대상 테이블인 emp를 두번 엑세스 하기 때문에 성능에 안좋다
'자격증 > SQLP' 카테고리의 다른 글
| [SQLP 친절한 SQL 튜닝 정리] 6장- DML 튜닝(파티션을 활용한 DML 튜닝) (0) | 2025.02.23 |
|---|---|
| [SQLP 친절한 SQL 튜닝 정리] 6장- DML 튜닝(Direct Path I/O 활용) (0) | 2025.02.21 |
| [SQLP 친절한 SQL 튜닝 정리] 5장- 소트튜닝(Sort Area를 적게 사용하는 SQL 작성) (0) | 2025.02.16 |
| [SQLP 친절한 SQL 튜닝 정리] 5장- 소트튜닝(소트가 발생하지 않도록 SQL 작성) (0) | 2025.02.12 |
| [SQLP 친절한 SQL 튜닝 정리] 5장- 소트튜닝(소트 연산에 대한 이해) (0) | 2025.02.12 |