[SQLP 친절한 SQL 튜닝 정리] 5장- 소트튜닝(인덱스를 이용한 소트 연산 생략)
SQLP를 준비하며 "친절한 sql 튜닝" 책 5장 소트튜닝 인덱스를 이용한 소트 연산생략 부분을 정리한 내용 입니다.
친절한SQL튜닝 도서
5장-소트튜닝
5.3 인덱스를 이용한 소트 연산 생략
5.3.1 Sort Order By 생략
인덱스는 항상 키 컬럼 순으로 정렬되어 있기 때문에, Order By 또는 Group By 절이 있어도 소트 연산을 생략할 수 있다.
SELECT
거래일시, 체결건수, 체결수량, 거래대금
FROM 종목거래
WHERE 종목코드 = 'KR123456'
ORDER BY 거래일시
- 인덱스 선두 컬럼을 [종목코드 + 거래일시] 순으로 구성하면 소트 연산을 생략할 수 있다.
- 소트 연산을 생략하므로 종목코드 = "KR123456" 조건을 만족하는 전체 레코드를 읽지 않고도 바로 결과집합을 출력할 수 있게 되었다(부분범위 처리 가능 상태)

- 인덱스 컬럼이 [종목코드] 단일 컬럼일 경우, 종목코드 ='KR123456' 조건을 만족하는 레코드를 인덱스에서 모두 읽고 많은 랜덤 엑세스가 발생한다. 또 모든 데이터를 다 읽어 거래순으로 정렬을 마치고 출력(부분범위 처리 불가)하므로 응답 속도가 느리다
5.3.2 Top N 쿼리
전체 결과 집합 중 상위N개 레코드만 선택하는 쿼리
오라클에서의 TopN 쿼리
SELECT * FROM (
SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM 종목거래
WHERE 종목코드 = 'KR123456'
AND 거래일시 >= '20180304'
ORDER BY 거래일시
)
WHERE ROWNUM <= 10
- 인덱스 [종목코드+거래일시] 구성
- 옵티마이저는 소트 연산을 생략하고, 인덱스를 스캔하다 열 개 레코드를 읽는 순간 멈춘다.
- 실행계획에 COUNT(STOPKEY)의 의미(Top N Stopkey 알고리즘)
- ROWNUM으로 지정한 건수만큼 결과 레코드를 얻으면 바로 멈춘다
SQL Server에서의 TopN 쿼리
SELECT TOP 10 거래일시, 체결건수, 체결수량, 거래대금
FROM 종목거래
WHERE 종목코드 = 'KR123456'
AND 거래일시 >= '20180304'
ORDER BY 거래일시
IBM DB2에서의 TopN 쿼리
SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM 종목거래
WHERE 종목코드 = 'KR123456'
AND 거래일시 >= '20180304'
ORDER BY 거래일시
FETCH FIRST 10 ROWS ONLY;
페이징 처리
3-Tier 환경에서 부분범위 처리는 페이징 처리를 통해 가능하다.
-- 페이징 처리 표준 패턴
SELECT *
FROM (
SELECT ROWNUM NO, A.*
FROM(
/* SQL BODY */
) A
WHERE ROWNUM <= (:page * 10 )
)
WHERE NO >= (:page-1)*10 +1
3-Tier 환경에서 부분범위 처리를 활용하기 위해 해야할 일
- 부분범위 처리 가능하도록 SQL을 작성. 부분범위 처리가 잘 작동하는지 쿼리 툴에서 테스트
- 작성한 SQL문을 페이징 처리용 표준 패턴 SQL BODY 부분에 붙여 넣는다.
부분범위 처리 가능하도록 SQL을 작성?
- 인덱스 사용 가능 하도록 조건절 구사
- NL 조인 위주로 처리
- Order by 절이 있어도 소트 연산을 생략할 수 있도록 인덱스 구성

- 완성 된 페이징 처리 SQL
- 실행계획에 소트 연산이 없고, COUNT(STOPKEY) 발생
페이징 처리ANTI 패턴
SELECT *
FROM (
SELECT ROWNUM NO, A.*
FROM(
SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM 종목거래
WHERE 종목코드 = 'KR123456'
AND 거래일시 >= '20180304'
ORDER BY 거래일시
) A
)
WHERE NO BETWEEN (:page-1)*10 + 1 AND (:page * 10 )
- ROWNUM 조건을 BETWEEN으로 변경하면, 'TOP N StopKey' 알고리즘이 작동하지 않는다.
- ORDER BY 절의 ROWNUM은 단순한 조건절이 아닌 'TOP N Stopkey'알고리즘을 작동하게 하는 열쇠다.
- 위 처럼 구성하면 COUT(STOPKEY)가 작동하지 않고, 전체 범위 처리를 한다.
부분범위 처리 가능하도록 SQL 작성하기
SELECT
*
FROM (
SELECT 계좌번호, 거래순번, 주문금액, 주문수량, 결제구분코드, 주문매체코드
FROM 거래
WHERE 거래일자 = :ord_dt
ORDER BY 계좌번호, 거래순번, 결제구분코드
)
WHERE rownum <= 50
- 거래_PK : [거래일자 + 계좌번호 + 거래순번]
- 거래_X01 : [계좌번호 + 거래순번 + 결제구분코드]
- 위 Top N 쿼리의 인덱스 구성으로는 소트 연산을 생략할 수 없기 때문에, 거래일자 조건에 해당하는 데이터를 모두 읽어 정렬을 마칠 때까지 기다려야 한다.
- [거래일자 + 계좌번호 + 거래순번 + 결제구분코드] 인덱스 추가 또는 PK 인덱스에 결제구분코드를 추가하면 소트 생략이 가능하지만, 인덱스를 최소한으로 유지해야 하기 때문에 적절하지 않다.
- PK가 [거래일자+계좌번호+거래순번]이고, 거래일자가 ‘=’ 조건이기 때문에, 같은 거래일자 데이터를 [계좌번호+거래순번]으로 정렬해 놓고 보면, 중복 레코드가 전혀 없다.
- 변별력이 없는 결제구분코드를 Order By 절에서 제거함으로 Sort Order by 오퍼레이션 없애 부분범위 처리가 가능해진다.
5.3.3 최소값/최대값 구하기

- 최소값/최대값을 구하는 SQL의 실행계획을 보면 SortAggregate 오퍼레이션이 나타난다.
- 전체 데이터를 정렬하진 않지만 전체 데이터를 읽으면서 값을 비교한다.
- 인덱스 구성이 올바를떄, 인덱스 리프블록 맨 왼쪽 으로 내려가서 첫 번째 읽는 값이 최소값이고, 맨 오른쪽으로 내려가서 첫 번째 읽는 값이 최대값이다.
인덱스를 이용해 최소/최대값 구하기 위한 조건
인덱스를 이용해 최소/최대 값을 구하려면, 조건절 컬럼과 MIN/MAX 함수 인자 컬럼이 모두 인덱스에 포함되어야 한다
즉, 테이블 엑세스가 발생하지 않아야 한다.
First Row StopKey(실행계획 상 'FIRST ROW' )
조건을 만족하는 레코드 하나를 찾았을 때 바로 멈춘다는 의미
인덱스 컬럼이 조건절과 MIN/MAX절에 모두 구성되어 있을 경우

- EMP_X1 : [DEPTNO + MGR + SAL]
- 조건절에 선두 컬럼이 있을 경우 Index Range Scan 가능
- 조건절과 MAX컬럼이 모두 인덱스에 포함되어 있고, 인덱스 선두 컬럼 DEPTNO, MGR이 모두 '=' 조건 이므로 두 조건을 만족하는 범위(Range) 가장 오른쪽에 있는 값 하나를 읽는다.


- EMP_X1 : [SAL + DEPTNO + MGR]
- 조건절에 인덱스 선두 컬럼이 없을 경우 Index Range Scan 불가
- InDex Full Scan 방식으로 인덱스 전체 레코드 중 가장 오른쪽에서 시작해 필터 조건인 DEPTNO = 30, MGR =7698 조건을 만족하는 레코드 하나를 찾으면 멈추면 된다.(First Row StopKey 알고리즘 작동)
조건절 컬럼과 MAX 컬럼 중 어느 하나가 인덱스에 포함돼 있지 않은 경우


- EMP_X1 : [DEPTNO + SAL]
- DEPT = 30 조건을 만족하는 MAX(SAL)은 쉽게 찾을 수 있으나, MGR 컬럼이 인덱스에 없으므로 MGR= 7698 조건은 테이블에서 필터링
- DEPTNO = 30 조건을 만족하는 '전체'레코드를 읽어 테이블에서 MGR = 7698 조건을 필터링 한 후 MAX(SAL) 값을 구하기 때문에 부분범위 처리 불가(First Row Stopkey 알고리즘 작동하지 않음)
Top N쿼리를 이용 해 최소/최대값 구하기


- Top N 쿼리에 작동하는 'Top N StopKey' 알고리즘은 모든 컬럼에 인덱스가 포함돼 있지 않아도 작동
- DEPTNO = 30 조건을 만족하는 가장 오른쪽부터 역순으로 스캔하면서 테이블을 엑세스 하다 MGR = 7698 조건을 만족하는 레코드 하나를 찾았을때 멈춘다.
5.3.4 이력 조회
이력 테이블
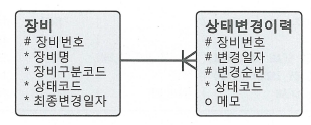
- 일반 테이블은 현재(최종)값만 저장하므로 변경 되기 이전의 값을 알수 없다. 값이 어떻게 변경돼 왔는지 이력을 조회할 필요가 있다면 이력 테이블을 따로 관리 해야 한다.
가장 단순한 이력 조회
SELECT 장비번호, 장비명, 상태코드
,(SELECT MAX(변경일자)
FROM 상태변경이력
WHERE 장비번호 = P.장비번호 ) AS 최종변경일자
FROM 장비 P
WHERE 장비구분코드 = 'A001'
- 상태변경이력_PK = [장비번호 + 변경일자 + 변경순번]
- 위와 같이 인덱스를 구성하게 되면 이력 조회 하는 서브쿼리에서 'First Row Stopkey' 알고리즘이 작동 한다.
점점 복잡해지는 이력 조회
SELECT
장비번호, 장비명, 상태코드
,SUBSTR(최종이력, 1, 8) AS 최종변경일자
,TO_NUMBER(SUBSTR(최종이력, 9, 4)) AS 최종변경 순번
FROM (
SELECT 장비번호, 장비명, 상태코드
,( SELECT MAX(H.변경일자 || LPAD(H.변경순번, 4))
FROM 상태변경이력 H
WHERE 장비번호 = P.장비번호 ) 최종이력
FROM 장비 P
WHERE 장비구분코드 = 'A001'
)
- 상태변경이력_PK = [장비번호 + 변경일자 + 변경순번]
- 인덱스 컬럼이 가공되었기 때문에 'First Row StopKey' 알고리즘이 작동하지 않는다.
- 장비별 상태변경 이력이 많다면 성능에 문제가 될 수 있음으로 아래 SQL 처럼 변경하는 것이 좋다.
SELECT
장비번호, 장비명, 상태코드
,(SELECT MAX(H.변경일자)
FROM 상태변경이력 H
WHERE 장비번호 = P.장비번호 ) AS 최종변경일자
,(SELECT MAX(H.변경순번)
FROM 상태변경이력 H
WHERE 장비번호 = P.장비번호
AND 변경일자 = (SELECT MAX(H.변경일자)
FROM 상태변경이력 H
WHERE 장비번호 = P.장비번호 )) AS 최종변경순번
FROM 장비 P
WHERE 장비구분코드 = 'A001'
- 쿼리가 복잡하고 상태변경이력을 세번 조회하는 비효율은 있지만, 'First Row Stopkey' 알고리즘이 잘 작동하므로 성능이 비교적 좋다.
INDEX_DESC 힌트 활용
SELECT
장비번호, 장비명
,SUBSTR(최종이력,9,4)) AS 최종변경순번
, SUBSTR(최종이력, 13) AS 최종상태코드
FROM (
SELECT
장비번호, 장비명
,(SELECT /*+ INDEX_DESC(X 상태변경이력_PX) */
변경일자 || LPAD(변경순번, 4) || 상태코드
FROM 상태변경이력 X
WHERE 장비번호 = P.장비번호
AND ROWNUM <=1) AS 최종이력
FROM 장비 P
WHERE 장비구분코드 = 'A001'
)
- 단순하게 쿼리하면서 성능을 높이기 위해 SQL 튜닝 전문가들이 전통적으로 사용해온 방식
- 인덱스 역순으로 읽도록 INDEX_DESC 힌트 사용, 첫번째 레코드에서 바로 멈추도록 ROWNUM <=1 사용
- 성능은 좋으나, 인덱스 구성이 완벽해야 쿼리가 작동한다.
SELECT
장비번호, 장비명
,SUBSTR(최종이력, 1, 8) 최종변경일자
,TO_NUMBER(SUBSTR(최종이력, 9 ,4)) AS 최종변경순번
,SUBSTR(최종이력, 13) 최종상태코드
FROM(
SELECT 장비번호, 장비명
,(SELECT 변경일자 || LPAD(변경순번, 4) || 상태코드
FROM( SELECT 장비번호, 변경일자, 변경순번, 상태코드
FROM 상태변경이력
WHERE 장비번호 = P.장비번호
ORDER BY 변경일자 DESC, 변경순번 DESC)
AND ROWNUM <= 1 ) AS 최종이력
FROM 장비 P
WHERE 장비구분코드 = 'A001'
)
- 오라클 12c부터 파싱 오류 없이 'Top N Stopkey' 알고리즘 작동
- [장비번호 = P.장비번호] 조건절이 인라인 뷰 안쪽으로 파고 들어간다(Predicate Pushing 쿼리변환)
- 혹시 인덱스 구성이 변경 되었을 때 'Top N Stopkey' 알고리즘이 작동하지 않아 성능이 느려질 순 있지만,쿼리 결과 집합은 보장
5.3.5 Sort Group By 생략
SELECT
REGION, AVG(AGE), COUNT(*)
FROM CUSTOMER
GROUP BY REGION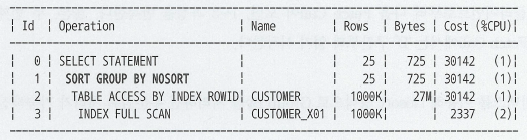
- region이 선두 컬럼인 인덱스를 이용하면, Sort Group By 연산을 생략할 수 있다.
Sort Group by 실행계획 수행

- 인덱스 'A'구간을 스캔하면서 테이블을 엑세스하다가 'B'를 만나는 순간, 그때까지 집계한 값을 운반 단위에 저장
- 'B'구간을 스캔하다 'C'를 만나는 순간, 그때까지 집계한 값을 운반단위에 저장
- 'C'구간을 스캔하다 'D'를 만나는 순간, 그때까지 집계한 값을 운반단위에 저장. ArraySize가 3이므로 지금까지 읽은 A,B,C에 대한 집계결과를 클라이언트에게 전송하고 다음 Fetch Call이 올때까지 기다린다.(추가 Fetch Call이 오지 않을 경우 작업은 여기서 끝남)
- 클라이언트로부터 다음 Fetch Call이 오면, 1~3 과정을 반복. 두 번 째 Fetch Call에서는 'D'구간부터 읽기 시작